Java 集合类学习 List 集合
List 集合
参考资料 java集合系列——List集合总结(六) 上面介绍完顶级接口,这里开始学习各个细分的接口
这个 List 接口主要的实现类有ArrayList、LinkedList、Vector、Stack 这几个
- ArrayList 是基于数组实现的,是一个数组队列。可以动态的增加容量!
- LinkedList 是基于链表实现的,是一个双向循环列表。可以被当做堆栈使用!
- Vector 是基于数组实现的,是一个矢量队列,是线程安全的!
- Stack 是基于数组实现的,是栈,它继承与 Vector,特性是 FILO(先进后出)!
虽然平时使用最多的是 Array,但是其他的实现类也要明白它的使用场景
- 当集合中对插入元素数据的速度要求不高,但是要求快速访问元素数据,则使用 ArrayList!
- 当集合中对访问元素数据速度不做要求不高,但是对插入和删除元素数据速度要求高的情况,则使用 LinkedList!
- 当集合中有多线程对集合元素进行操作时候,则使用 Vector!但是现在 BVector 现在一般不再使用,如需在多线程下使用,可以用 CopyOnWriteArrayList
- 当集合中有需求是希望后保存的数据先读取出来,则使用Stack!例如像浏览器的历史记录那就是先进后出的
使用事后分析法看下这个运行时间
....开始测试插入元素..........
ArrayList : 插入 100000 元素, 使用的时间是 970 ms
LinkedList : 插入 100000 元素, 使用的时间是 17 ms
Vector : 插入 100000 元素, 使用的时间是 968 ms
Stack : 插入 100000 元素, 使用的时间是 888 ms
....开始测试读取元素..........
ArrayList : 随机读取 100000 元素, 使用的时间是 6 ms
LinkedList : 随机读取 100000 元素, 使用的时间是 10255 ms
Vector : 随机读取 100000 元素, 使用的时间是 8 ms
Stack : 随机读取 100000 元素, 使用的时间是 4 ms
....开始测试删除元素..........
ArrayList : 删除 100000 元素, 使用的时间是 1460 ms
LinkedList : 删除 100000 元素, 使用的时间是 9 ms
Vector : 删除 100000 元素, 使用的时间是 1472 ms
Stack : 删除 100000 元素, 使用的时间是 894 ms
List 中删除元素
迭代器的方式
Iterator<String> iterable = list.iterator();
while (iterable.hasNext()){
String s = iterable.next();
if (s.equals("123")) {
iterable.remove();
}
}
使用 Stream 的方式
List<String> list1 = list.stream()
.filter(list2 -> !list2.equals("123"))
.collect(Collectors.toList());
使用 removeIf() 方法
Java8 开始,可以使用 Collection#removeIf() 方法删除满足特定条件的元素,如
List<Integer> list = new ArrayList<>();
for (int i = 1; i <= 10; ++i) {
list.add(i);
}
list.removeIf(filter -> filter % 2 == 0); /* 删除list中的所有偶数 */
System.out.println(list); /* [1, 3, 5, 7, 9] */
ArrayList 原理部分
参考资料 Java—List集合详解
ArrayList 是一个数组队列,相当于动态数组(静态数组就是原始的 type[] var; 这种)
ArrayList 中的操作不是线程安全的!所以在单线程中才使用 ArrayList,而在多线程中一般用 CopyOnWriteArrayList
ArrayList 包含了两个重要的对象:elementData 和 size,其中 elementData 是 Object[] 类型的数组,它保存了添加到ArrayList中的元素。而这个 elementData 其实就是动态数组,能通过构造函数 ArrayList(int initialCapacity) 来执行它的初始容量为 initialCapacity;如果通过不含参数的构造函数 ArrayList() 来创建 ArrayList,则 elementData 的容量默认是 10。
elementData 数组的大小会根据 ArrayList 容量的增长而动态的增长,而 size 则是动态数组的实际大小。当 ArrayList 容量不足以容纳全部元素时,ArrayList 会重新设置容量:新的容量=“(原始容量x3)/2 + 1”
ArrayList 底层采用数组实现,当使用不带参数的构造方法生成 ArrayList 对象时,底层实际会生成一个长度为 10 的 Object 类型数组,如果增加的元素个数超过 10 个,则 ArrayList 底层会新生成一个数组,长度为原数组的 1.5 倍+1,然后将原数组的内容复制到新数组中去,后续增加的内容都会放入新数组中,当新数组无法容纳新元素时,又会重复上述步骤。
ArrayList 的删除操作
public E remove(int index) {
Objects.checkIndex(index, size); // 先检查是否超过下标
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i); // 复制数组这个操作的方法是 native 的
es[size = newSize] = null;
}
实际上删除操作是通过复制数组再拼接数组来做的,下面的操作都是一样的,所以直接简化代码了
ArrayList 访问元素
而 ArrayList 访问元素自然采用的是下标的方式
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index]; // 直接通过数组的下标来读取元素
}
ArrayList 插入元素
ArrayList 插入时候要判断容量
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 判断是否要增容
elementData[size++] = e;
return true;
}
ArrayList 判断是否需要扩容
如果通过无参构造的话,初始数组容量为 0,当真正对数组进行添加时,才真正分配容量。
每次按照1.5倍(位运算)的比率通过 copeOf 的方式扩容。
在 JKD1.6 中实现是,如果通过无参构造的话,初始数组容量为 10,每次通过 copeOf 的方式扩容后容量为原来的 1.5 倍
看下面的添加函数的方法:
public boolean add(E e) {
//确保内部容量(通过判断,如果够则不进行操作;容量不够就扩容来确保内部容量)
ensureCapacityInternal(size + 1); // 1、Increments modCount!!
elementData[size++] = e;//2、
return true;
}
1、 ensureCapacityInternal 方法名的英文大致是 “确保内部容量”,就是用来 判断是否需要扩容的函数,size 表示的是执行添加之前的元素个数,并非 ArrayList 的容量,容量应该是数组 elementData 的长度。ensureCapacityInternal 该方法通过将现有的元素个数数组的容量比较。看如果需要扩容,则扩容。
2、是将要添加的元素放置到相应的数组中。
下面具体看 ensureCapacityInternal(size + 1); 这里是 1.6 的,它初始值是 10
// ① 是如何判断和扩容的。
private void ensureCapacityInternal(int minCapacity) {
//如果实际存储数组 是空数组,则最小需要容量就是默认容量
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//如果数组(elementData)的长度小于最小需要的容量(minCapacity)就扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
以上:
- elementData 是用来存储实际内容的数组。
- minExpand 是最小扩充容量。
- DEFAULTCAPACITY_EMPTY_ELEMENTDATA 共享的空数组实例用于默认大小的空实例。
根据传入的最小需要容量 minCapacity 来和数组的容量长度对比,若 minCapacity 大于或等于数组容量,则需要进行扩容。
ArrayList 动态扩容
/*
*增加容量,以确保它至少能容纳
*由最小容量参数指定的元素数。
* @param mincapacity所需的最小容量
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//>>位运算,右移动一位。 整体相当于newCapacity =oldCapacity + 0.5 * oldCapacity
// jdk1.7采用位运算比以前的计算方式更快
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//jdk1.7这里增加了对元素个数的最大个数判断,jdk1.7以前是没有最大值判断的,MAX_ARRAY_SIZE 为int最大值减去8(不清楚为什么用这个值做比较)
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 最重要的复制元素方法
elementData = Arrays.copyOf(elementData, newCapacity);
}
综上所述,ArrayList 相当于在没指定 initialCapacity 时就是会使用延迟分配对象数组空间,当第一次插入元素时才分配 10(默认)个对象空间。
- 向数组中添加第一个元素时,数组容量为10.
- 向数组中添加到第10个元素时,数组容量仍为10.
- 向数组中添加到第11个元素时,数组容量扩为15.
- 向数组中添加到第16个元素时,数组容量扩为22.
LinkedList(队列)
LinkedList 是一个继承于 AbstractSequentialList(抽象顺序 List)的 双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 最常用的用途就是队列
它也继承自队列这个接口,所以也是先进先出
Queue<String> queue = new LinkedList<>();
它的常用方法:
| 用途 | throw Exception | 返回 false 或 null |
|---|---|---|
| 添加元素到队尾 | add(E e) | boolean offer(E e) |
| 取队首元素并删除 | E remove() | E poll() |
| 取队首元素但不删除 | E element() | E peek() |
右边的就是它作为队列的方法
作为队列的使用例:
public class Main {
public static void main(String[] args) {
Queue<String> q = new LinkedList<>();
// 添加3个元素到队列:
q.offer("apple");
q.offer("pear");
q.offer("banana");
// 队首永远都是 apple,因为 peek() 不会删除它:
System.out.println(q.peek()); // apple
System.out.println(q.peek()); // apple
// 移除首元素并返回
System.out.println(q.poll()); // apple
}
}
LinkedList 内部结构
LinkedList 底层的数据结构是基于双向循环链表的,且头结点中不存放数据,如下:
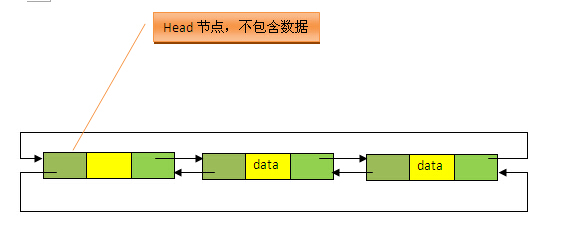
LinkedList 包含两个重要的成员:header 和 size。
- header 是双向链表的表头,它是双向链表节点所对应的类 Entry 的实例;
- size 是双向链表中节点的个数。
既然是双向链表,那么必定存在一种数据结构——我们可以称之为节点,节点实例保存业务数据,前一个节点的位置信息和后一个节点位置信息,如下图所示:

Entry 中包含成员变量:previous, next, element
- previous 是该节点的上一个节点
- next 是该节点的下一个节点
- element 是该节点所包含的值。
访问性 LinkedList 实际上是通过 双向链表 去实现的。既然是双向链表,那么它的顺序访问会非常高效,而随机访问效率比较低。
LinkedList 是双向链表,但是它也实现了 List 接口,也就是说,它实现了 get(int index)、remove(int index) 等根据索引值来获取、删除节点的函数。
它增删一个元素会比较方便
public boolean add(E e) {
linkLast(e);
return true;
}
// 因为是双向链表,所以直接更改最后一个元素的指向就行了
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
前面说了 LinkedList 继承自 AbstractSequentialList,AbstractSequentialList 内部优化了对于链表这种 List 随机访问的能力,内部维护一个计数索引值
例如,当程序调用 get(int index) 方法时,首先会比较 Location 和双向链表长度的 1/2;如果前者大,则从链表头开始向后查找,直到 Location 位置;否则,从链表末尾开始向前查找,直到 Location 位置。(注意,这个不是二分法,它还是遍历实现的)
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
所以每次随机访问都是需要遍历一遍数组,而当访问的元素位于 List 中间,那就是花费最长的时候
CopyOnWriteArrayList
参考资料 先简单说一说Java中的CopyOnWriteArrayList 参考资料 ReentrantLock vs synchronized on CPU level?
从 JDK1.5 开始 Java 并发包里提供了两个使用 CopyOnWrite 机制实现的并发容器,它们是 CopyOnWriteArrayList 和 CopyOnWriteArraySet。CopyOnWrite 容器非常有用,可以在非常多的并发场景中使用到。
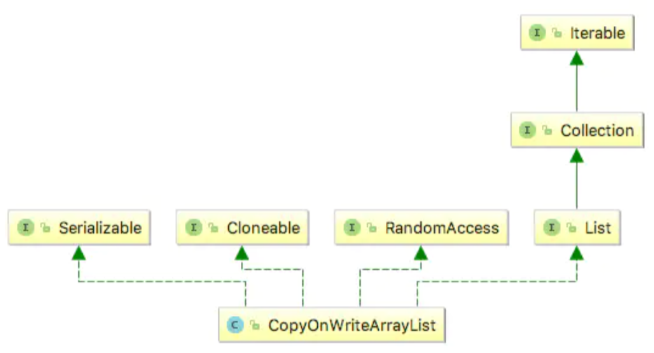
CopyOnWriteArrayList 是 ArrayList 的线程安全变体,其中通过创建底层数组的新副本来实现所有可变操作(添加,设置等)。
什么是 Copy-On-Write,顾名思义,在计算机中就是当你想要对一块内存进行修改时,不在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后就将指向原来内存指针指向新的内存,原来的内存就可以被回收掉了
如下,它的 add 方法源码(注意 9 之前采用的还是 ReentrantLock 锁,后来之所以要换成 synchronized 是因为 JDK5 之后 synchronized 的性能也不一定差过 ReentrantLock,官方带头使用 synchronized 让程序员放心使用 synchronized)
public boolean add(E e) {
synchronized (lock) {
Object[] es = getArray();
int len = es.length;
es = Arrays.copyOf(es, len + 1);
es[len] = e;
setArray(es);
return true;
}
}
add() 在添加集合的时候加上了锁,保证了同步,避免了多线程写的时候会 Copy 出 N 个副本出来。
这是一种用于程序设计中的优化策略,是一种延时懒惰策略
通常使用成本太高,但是当遍历操作大大超过突变时,它可能比替代方法更有效,并且当您不能或不想同步遍历但需要排除并发线程之间的干扰时非常有用。
使用例
public class Temp {
public static void main(String[] args) throws InterruptedException {
List<Integer> count = new CopyOnWriteArrayList<>();
CountDownLatch countDownLatch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
new Thread(()->{
for (int j = 0; j < 100; j++) {
count.add(1);
}
countDownLatch.countDown();
}).start();
}
countDownLatch.await();
System.out.println(count.size()); // 检查是否为 1000个元素
}
}
优缺点
缺点: 1、耗内存(集合复制) 2、实时性不高(注意,它只保证最终一致性,不保证实时性)
优点: 1、数据一致性完整,为什么?因为加锁了,并发数据不会乱 2、解决了像 ArrayList、Vector 这种集合多线程遍历迭代问题,Vector 虽然线程安全,只不过是加了 synchronized 关键字,迭代问题完全没有解决!
CopyOnWriteArrayList 使用场景
1、读多写少(白名单,黑名单,商品类目的访问和更新场景),为什么?因为写的时候会复制新集合 2、集合不大,为什么?因为写的时候会复制新集合 3、实时性要求不高,为什么,因为有可能会读取到旧的集合数据
Stack
| 方法 | 描述 |
|---|---|
| boolean empty() | 测试堆栈是否为空。 |
| Object peek( ) | 查看堆栈顶部的对象,但不从堆栈中移除它。 |
| Object pop( ) | 移除堆栈顶部的对象,并作为此函数的值返回该对象。 |
| Object push(Object element) | 把项压入堆栈顶部。 |
| int search(Object element) | 返回对象在堆栈中的位置,以 1 为基数。 |
这个没什么好说,用到再补充